
ImageNet 已经成为全球最大的图像识别数据库,每年一度的比赛也牵动着各大巨头公司的心弦,如今图像识别已经能做到很高的水准。下一步是图像理解,ImageNet 创始人李飞飞开启了Visual Genome(视觉基因组)计划,要把语义和图像结合起来,推动人工智能的进一步发展。近日 Visual Genome 论文发布。
几年前,机器学习的技术突破,让计算机学会了识别照片中的物体,而且非常准确。现在的问题是,计算机能否带来另一个飞跃:学会理解相片中究竟发生着什么事。
一个叫 Visual Genome 的图像数据库,可能会推动计算机实现这个目标。它由斯坦福计算机视觉教授、人工智能实验室主任李飞飞和几个同事开发,我们知道李飞飞教授过去创建了 ImageNet,而 Visual Genome 是后 ImageNet 时代计算机视觉在理解图片上的训练和测试数据集。
在 Visual Genome 的官方网站上,把它定义为:Visual Genome 是一个数据集,知识库,不断努力把结构化的图像概念和语言连接起来。
网站:https://visualgenome.org
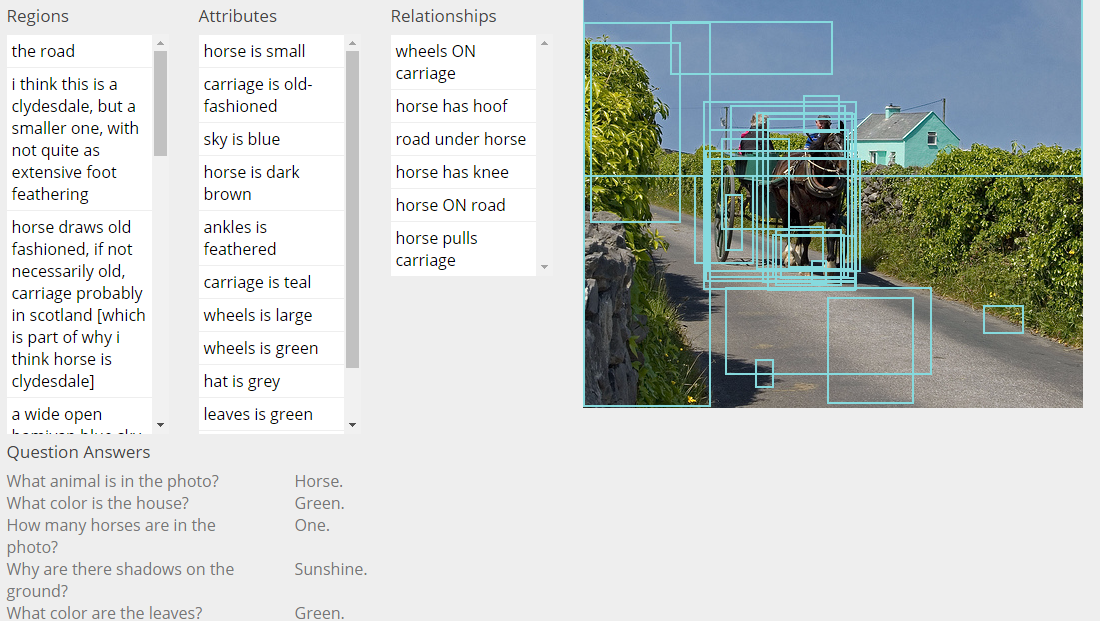
目前包含:108249 张图片,420 万对区域的描述(Region Descriptions),170 万视觉问答(Visual Question Answers),210 万对象案例(Object Instances),180 万属性(Attributes),180 万关系(Relationships).论文全文Visual Genome:Connecting Language and Vision Using Crowdsourced Dense Image Annotations,是对数据集的说明,数据的中文说明可以查看:http://www.yangfenzi.com/keji/59566.html 。所有的东西都映射到 Wordnet Synsets。
教会计算机解析视觉图像是人工智能非常重要的任务,这不久能带来更多有用的视觉算法,而且也能训练计算机更为高效的沟通。毕竟,在表达真实世界的时候,语言总是受到很大的限制。
摘要
尽管在感知的任务上(例如图像分类)计算机有很多进展,但是在认知的任务上(例如图像描述和问答),计算机表现的不怎么样。如果我们不仅仅诉求识别出图像,而要深究我们视觉世界的意义,那么认知是最核心的任务。被用于解决图片内容丰富的认知任务的模型,依然使用给感知任务设计的相同数据集来训练。要在认知任务中获得成功,模型需要理解对象和物体之间的交互和关系。当问道:“这个人正在骑着什么交通工具?”的时候,计算机需要识别出图片中的物体,以及里面的关系“骑行”(人、马车)和“拉车”(马、马车),这样才能正确回答“这个人正坐着马车”。
在这篇论文中,我们介绍了 Visual Genome 数据集,以及使用这种关系进行建模。我们收集了对象、属性、图片里关系的密集注释,以学习这些模型。特别的,我们的数据集包括了超过 10 万张图片,每一张图片都包含了平均 21 个对象,18 种属性和 18 种物体之间的关系。我们规范化了从对象、属性、关系、区域描述里的名词和短语和问答对到 WordNet 同义词集的关系。这些注释代表了图像描述、属性、关系和问答里最密集、规模最大的数据集。
visual genome官网含有丰富的数据集和说明,从region,objects,Attributes,Relationships,clustering,canonicalization,question Answers角度说明标签的分布,而且用可视化的方法展示数据。官网还提供团队的相关论文,图片标签示例和以文搜图,而且这些数据全部开源。
根据官网说明,VQA的问题主要如下。
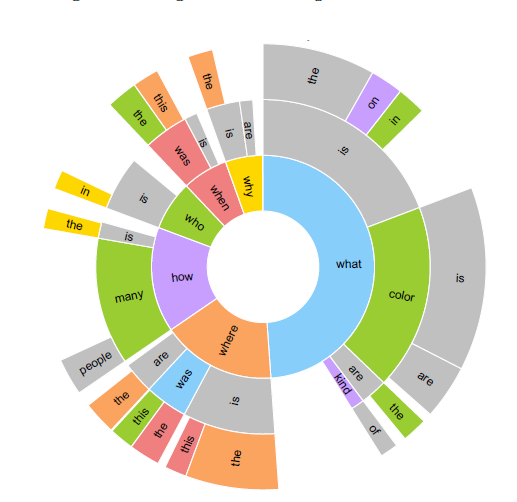
但考虑到决赛需要限制问题的开放性,暂定将问题限制于动物的种类,颜色,动物的相对位置,动物的数量。
现在我们需要基于CNN的智能问答效果。
Train a deeper LSTM and normalized CNN Visual Question Answering model. This current code can get 58.16 on Open-Ended and 63.09 on Multiple-Choice on test-standard split
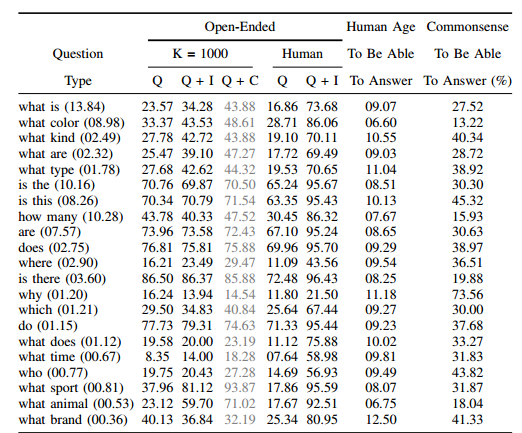
only considers questions whose answers come from a predefined closed world of 16 basic colors or 894 object categories. also considers questions generated from templates from a fixed vocabulary of objects, attributes, relationships between objects, etc. In contrast, our proposed task involves open-ended, free-form questions and answers provided by humans.
Baselines We implemented the following baselines: 1) random: We randomly choose an answer from the top 1K answers of the VQA train/val dataset. 2) prior (“yes”): We always select the most popular answer (“yes”) for both the open-ended and multiple-choice tasks. Note that “yes” is always one of the choices for the multiple-choice questions. 3) per Q-type prior: For the open-ended task, we pick the most popular answer per question type (see the appendix for details). For the multiple-choice task, we pick the answer (from the provided choices) that is most similar to the picked answer for the open-ended task using cosine similarity in Word2Vec[37] feature space. 4) nearest neighbor: Given a test image, question pair, we first find the K nearest neighbor questions and associated images from the training set. See appendix for details on how neighbors are found. Next, for the open-ended task, we pick the most frequent ground truth answer from this set of nearest neighbor question, image pairs. Similar to the “per Q-type prior” baseline, for the multiple-choice task, we pick the answer (from the provided choices) that is most similar to the picked answer for the open-ended task using cosine similarity in Word2Vec[37] feature space.
Question Channel: This channel provides an embedding for the question. We experiment with three embeddings – 1) Bag-of-Words Question (BoW Q): The top 1,000 words in the questions are used to create a bag-of-words representation.Since there is a strong correlation between the words that start a question and the answer (see Fig. 5), we find the top 10 first, second, and third words ofthe questions and create a 30 dimensional bag-of-words representation. These features are concatenated to get a 1,030-dim embedding for the question. 2) LSTM Q: An LSTM with one hidden layer is used to obtain 1024-dim embedding for the question. Each question word is encoded with 300-dim embedding by a fully-connected layer + tanh non-linearity which is then fed to the LSTM. The input vocabulary to the embedding layer consists of all the question words seen in the training dataset. 3) deeper LSTM Q: An LSTM with two hidden layers is used to obtain 2048-dim embedding for the question, followed by a fully-connected layer + tanh non-linearity to transform 2048-dim embedding to 1024-dim. The question words are encoded in the same way as in LSTM Q.
##Basic Statistics Total images: 108,077 Average image size (px): 500.14 Maximum image size (px): 1,280 Minimum image size (px): 72 Total region descriptions: 4,297,502 Total image object instances: 1,366,673 Unique image objects: 75,729 Total object-object relationship instances: 1,531,448 Unique relationships: 40,480 Total attribute-object instances: 1,670,182 Unique attributes: 40,513 Total Scene Graphs: 108,249 Total Region Graphs: 3,788,715 Total Question Answers: 1,773,258
Common Statistics
| Average number of objects | Average number of relationships | Average number of attributes | |
|---|---|---|---|
| Per region annotation | 1.01 | 0.63 | 0.77 |
| Per image | 21.24 | 17.68 | 16.08 |


###Learning to Answer Questions from Image Using Convolutional Neural Network 论文摘要,模型,结论的在线说明网站:http://conviqa.noahlab.com.hk/project.html
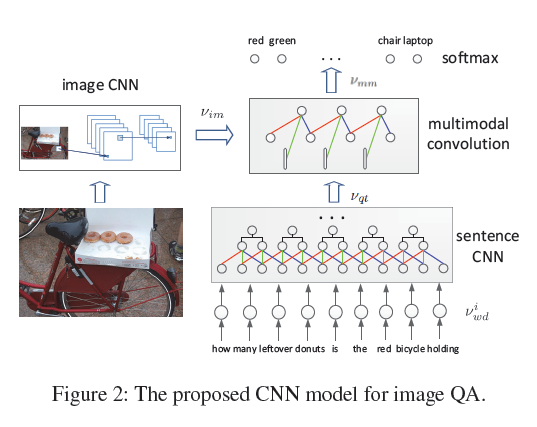


In this paper, $s_rf$ is chosen as 3 for the convolution process. The
input of the first convolution layer for the sentence CNN is the word embeddings of the question:

对象:天竺鼠,松鼠,梅花鹿,狐狸,狗,狼,猫,花栗鼠,长颈鹿,驯鹿,鬣狗,黄鼠狼,人,画,草坪,树,帽子,布偶。(总共18种对象)
位置关系:上边,下边,左边,右边,旁边
属性:白,黑,橙,棕
分析:在cloudCV上,运用Deeper LSTM+ normalized CNN,代码见here 得到结果如下:
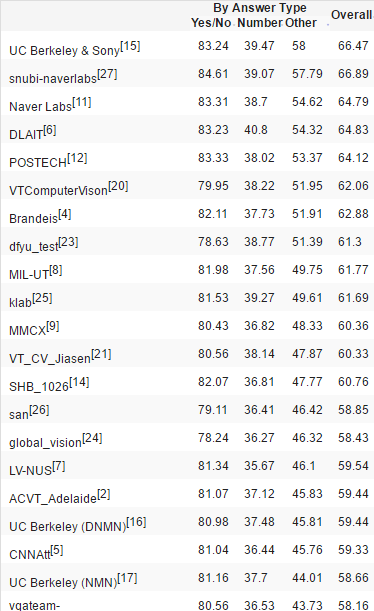
由此可以看出数量的准确率在30%-40%,具体可参考here.
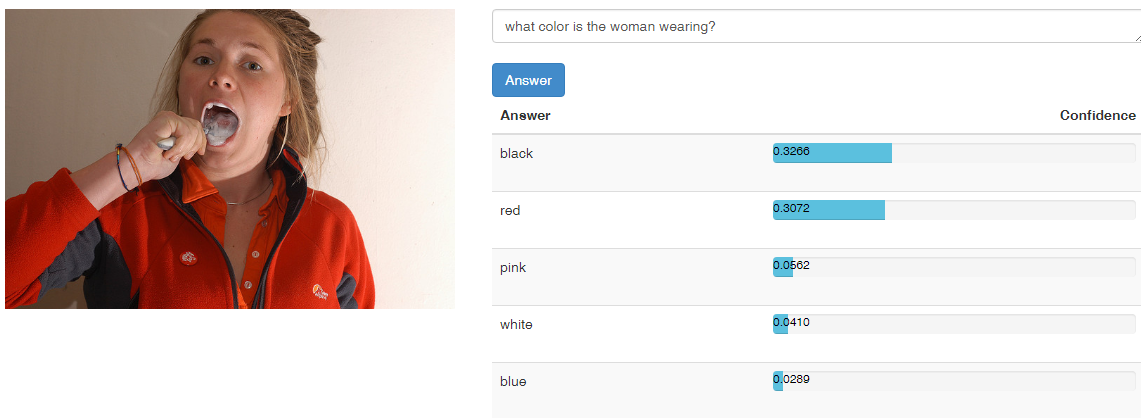
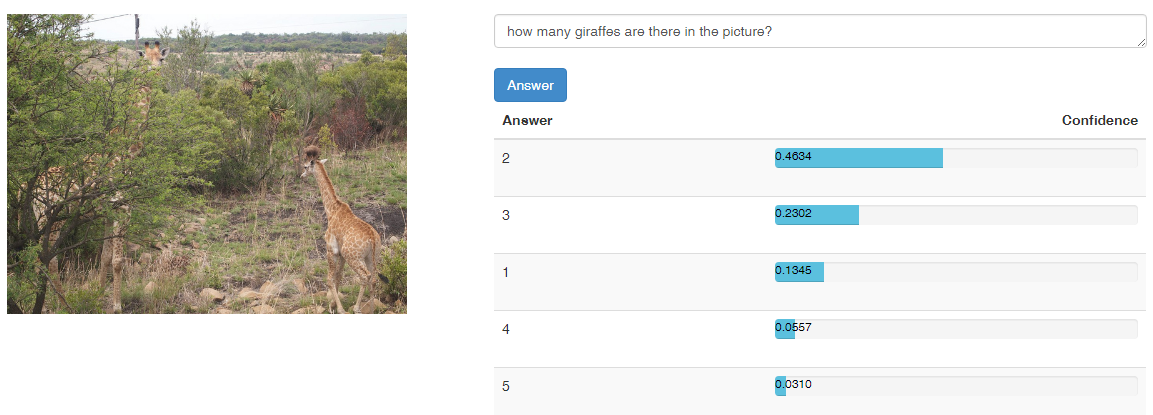
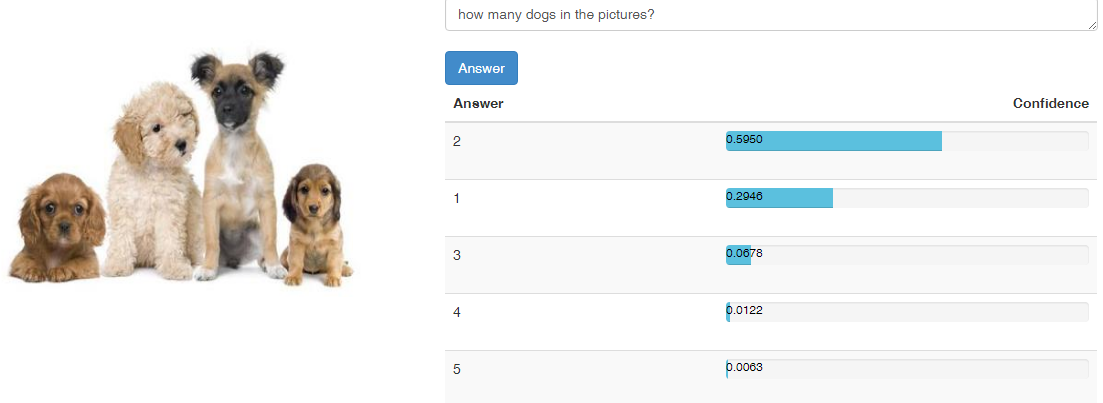
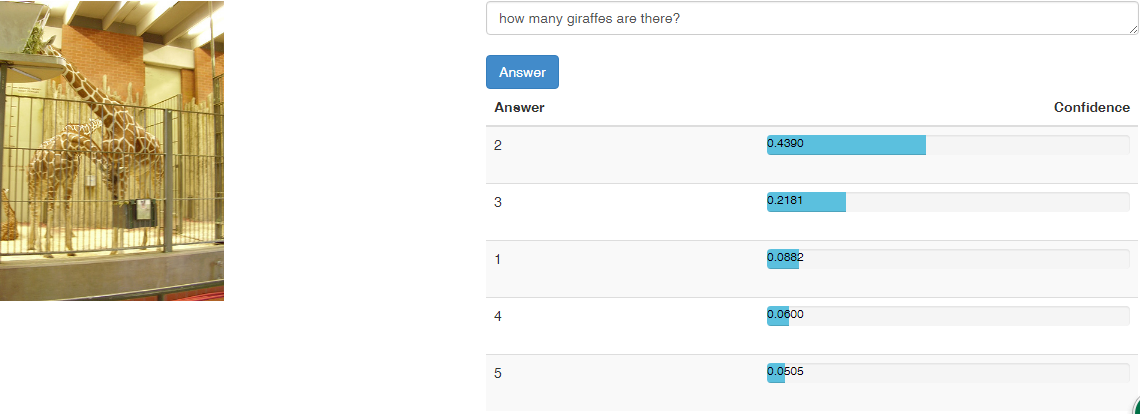
问题类型
类型1:动物类型 20%
图片中有什么动物?
类型2:动物数量 20%
图片中有几只动物? 图中黑色的狗有几条?
类型3:简单颜色属性或者位置关系 60%
猫在哪里? 图中的猫是什么颜色?